 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Frontier LLMs on PhD-Level Mathematical Reasoning: A Benchmark on a Textbook in Theoretical Computer Science about Randomized Algorithms
Dec 16, 2025The rapid advancement of large language models (LLMs) has led to significant breakthroughs in automated mathematical reasoning and scientific discovery. Georgiev, G${ó}$mez-Serrano, Tao, and Wagner [GGSTW+25] demonstrate that AI systems can explore new constructions and improve existing bounds, illustrating the growing potential of LLMs to accelerate mathematical discovery. Similarly, Bubeck et al. [BCE+25] show that GPT-5 can meaningfully contribute to scientific workflows, from proposing hypotheses to generating proofs and analyses. Despite these advances, a rigorous evaluation of these models on canonical, graduate-level mathematical theory remains necessary to understand their baseline reasoning capabilities. In this paper, we present a comprehensive benchmark of four frontier models: GPT-5-Thinking, Gemini-3-Pro, Claude-Sonnet-4.5-Thinking, and Grok-4 against the classic curriculum of Randomized Algorithms by Motwani and Raghavan [MR95]. We tasked each model with generating formal LaTeX proofs for a series of lemmas and exercises spanning the textbook. We find that while the top-tier models (Gemini, and Claude) achieve a high accuracy rate (approx. 66%), demonstrating a robust grasp of probabilistic method and formal logic, other models lag significantly in consistency (approx. 40%). We provide a qualitative analysis of the generated proofs, highlighting differences in conciseness, hallucination rates, and logical structure. Our results suggest that while frontier models have reached a threshold of proficiency suitable for graduate-level pedagogical assistance and formalization, significant variance exists in their reliability for rigorous mathematical derivation. The code and the full set of LLM-generated responses are open-sourced and publicly available at https://github.com/magiclinux/math_benchmark_probability.
Your Vision-Language Model Can't Even Count to 20: Exposing the Failures of VLMs in Compositional Counting
Oct 06, 2025Vision-Language Models (VLMs) have become a central focus of today's AI community, owing to their impressive abilities gained from training on large-scale vision-language data from the Web. These models have demonstrated strong performance across diverse tasks, including image understanding, video understanding, complex visual reasoning, and embodied AI. Despite these noteworthy successes, a fundamental question remains: Can VLMs count objects correctly? In this paper, we introduce a simple yet effective benchmark, VLMCountBench, designed under a minimalist setting with only basic geometric shapes (e.g., triangles, circles) and their compositions, focusing exclusively on counting tasks without interference from other factors. We adopt strict independent variable control and systematically study the effects of simple properties such as color, size, and prompt refinement in a controlled ablation. Our empirical results reveal that while VLMs can count reliably when only one shape type is present, they exhibit substantial failures when multiple shape types are combined (i.e., compositional counting). This highlights a fundamental empirical limitation of current VLMs and motivates important directions for future research.
T2VWorldBench: A Benchmark for Evaluating World Knowledge in Text-to-Video Generation
Jul 24, 2025Text-to-video (T2V) models have shown remarkable performance in generating visually reasonable scenes, while their capability to leverage world knowledge for ensuring semantic consistency and factual accuracy remains largely understudied. In response to this challenge, we propose T2VWorldBench, the first systematic evaluation framework for evaluating the world knowledge generation abilities of text-to-video models, covering 6 major categories, 60 subcategories, and 1,200 prompts across a wide range of domains, including physics, nature, activity, culture, causality, and object. To address both human preference and scalable evaluation, our benchmark incorporates both human evaluation and automated evaluation using vision-language models (VLMs). We evaluated the 10 most advanced text-to-video models currently available, ranging from open source to commercial models, and found that most models are unable to understand world knowledge and generate truly correct videos. These findings point out a critical gap in the capability of current text-to-video models to leverage world knowledge, providing valuable research opportunities and entry points for constructing models with robust capabilities for commonsense reasoning and factual generation.
T2VTextBench: A Human Evaluation Benchmark for Textual Control in Video Generation Models
May 08, 2025Thanks to recent advancements in scalable deep architectures and large-scale pretraining, text-to-video generation has achieved unprecedented capabilities in producing high-fidelity, instruction-following content across a wide range of styles, enabling applications in advertising, entertainment, and education. However, these models' ability to render precise on-screen text, such as captions or mathematical formulas, remains largely untested, posing significant challenges for applications requiring exact textual accuracy. In this work, we introduce T2VTextBench, the first human-evaluation benchmark dedicated to evaluating on-screen text fidelity and temporal consistency in text-to-video models. Our suite of prompts integrates complex text strings with dynamic scene changes, testing each model's ability to maintain detailed instructions across frames. We evaluate ten state-of-the-art systems, ranging from open-source solutions to commercial offerings, and find that most struggle to generate legible, consistent text. These results highlight a critical gap in current video generators and provide a clear direction for future research aimed at enhancing textual manipulation in video synthesis.
T2VPhysBench: A First-Principles Benchmark for Physical Consistency in Text-to-Video Generation
May 01, 2025Text-to-video generative models have made significant strides in recent years, producing high-quality videos that excel in both aesthetic appeal and accurate instruction following, and have become central to digital art creation and user engagement online. Yet, despite these advancements, their ability to respect fundamental physical laws remains largely untested: many outputs still violate basic constraints such as rigid-body collisions, energy conservation, and gravitational dynamics, resulting in unrealistic or even misleading content. Existing physical-evaluation benchmarks typically rely on automatic, pixel-level metrics applied to simplistic, life-scenario prompts, and thus overlook both human judgment and first-principles physics. To fill this gap, we introduce \textbf{T2VPhysBench}, a first-principled benchmark that systematically evaluates whether state-of-the-art text-to-video systems, both open-source and commercial, obey twelve core physical laws including Newtonian mechanics, conservation principles, and phenomenological effects. Our benchmark employs a rigorous human evaluation protocol and includes three targeted studies: (1) an overall compliance assessment showing that all models score below 0.60 on average in each law category; (2) a prompt-hint ablation revealing that even detailed, law-specific hints fail to remedy physics violations; and (3) a counterfactual robustness test demonstrating that models often generate videos that explicitly break physical rules when so instructed. The results expose persistent limitations in current architectures and offer concrete insights for guiding future research toward truly physics-aware video generation.
Can You Count to Nine? A Human Evaluation Benchmark for Counting Limits in Modern Text-to-Video Models
Apr 05, 2025Generative models have driven significant progress in a variety of AI tasks, including text-to-video generation, where models like Video LDM and Stable Video Diffusion can produce realistic, movie-level videos from textual instructions. Despite these advances, current text-to-video models still face fundamental challenges in reliably following human commands, particularly in adhering to simple numerical constraints. In this work, we present T2VCountBench, a specialized benchmark aiming at evaluating the counting capability of SOTA text-to-video models as of 2025. Our benchmark employs rigorous human evaluations to measure the number of generated objects and covers a diverse range of generators, covering both open-source and commercial models. Extensive experiments reveal that all existing models struggle with basic numerical tasks, almost always failing to generate videos with an object count of 9 or fewer. Furthermore, our comprehensive ablation studies explore how factors like video style, temporal dynamics, and multilingual inputs may influence counting performance. We also explore prompt refinement techniques and demonstrate that decomposing the task into smaller subtasks does not easily alleviate these limitations. Our findings highlight important challenges in current text-to-video generation and provide insights for future research aimed at improving adherence to basic numerical constraints.
Text-to-Image Diffusion Models Cannot Count, and Prompt Refinement Cannot Help
Mar 10, 2025



Generative modeling is widely regarded as one of the most essential problems in today's AI community, with text-to-image generation having gained unprecedented real-world impacts. Among various approaches, diffusion models have achieved remarkable success and have become the de facto solution for text-to-image generation. However, despite their impressive performance, these models exhibit fundamental limitations in adhering to numerical constraints in user instructions, frequently generating images with an incorrect number of objects. While several prior works have mentioned this issue, a comprehensive and rigorous evaluation of this limitation remains lacking. To address this gap, we introduce T2ICountBench, a novel benchmark designed to rigorously evaluate the counting ability of state-of-the-art text-to-image diffusion models. Our benchmark encompasses a diverse set of generative models, including both open-source and private systems. It explicitly isolates counting performance from other capabilities, provides structured difficulty levels, and incorporates human evaluations to ensure high reliability. Extensive evaluations with T2ICountBench reveal that all state-of-the-art diffusion models fail to generate the correct number of objects, with accuracy dropping significantly as the number of objects increases. Additionally, an exploratory study on prompt refinement demonstrates that such simple interventions generally do not improve counting accuracy. Our findings highlight the inherent challenges in numerical understanding within diffusion models and point to promising directions for future improvements.
Scaling Law Phenomena Across Regression Paradigms: Multiple and Kernel Approaches
Mar 03, 2025Recently, Large Language Models (LLMs) have achieved remarkable success. A key factor behind this success is the scaling law observed by OpenAI. Specifically, for models with Transformer architecture, the test loss exhibits a power-law relationship with model size, dataset size, and the amount of computation used in training, demonstrating trends that span more than seven orders of magnitude. This scaling law challenges traditional machine learning wisdom, notably the Oscar Scissors principle, which suggests that an overparametrized algorithm will overfit the training datasets, resulting in poor test performance. Recent research has also identified the scaling law in simpler machine learning contexts, such as linear regression. However, fully explaining the scaling law in large practical models remains an elusive goal. In this work, we advance our understanding by demonstrating that the scaling law phenomenon extends to multiple regression and kernel regression settings, which are significantly more expressive and powerful than linear methods. Our analysis provides deeper insights into the scaling law, potentially enhancing our understanding of LLMs.
Low-Power Computer Vision: Status, Challenges, Opportunities
Apr 15, 2019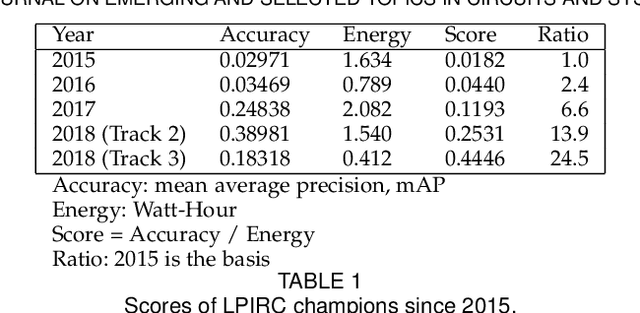
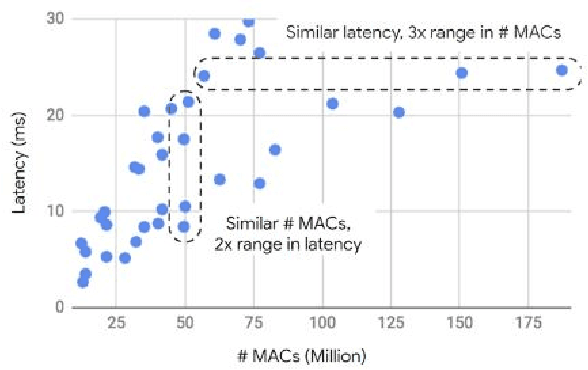
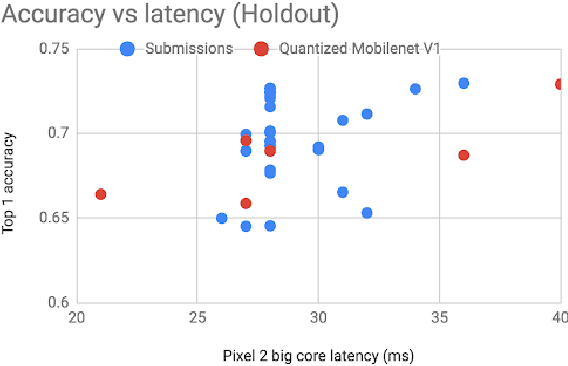
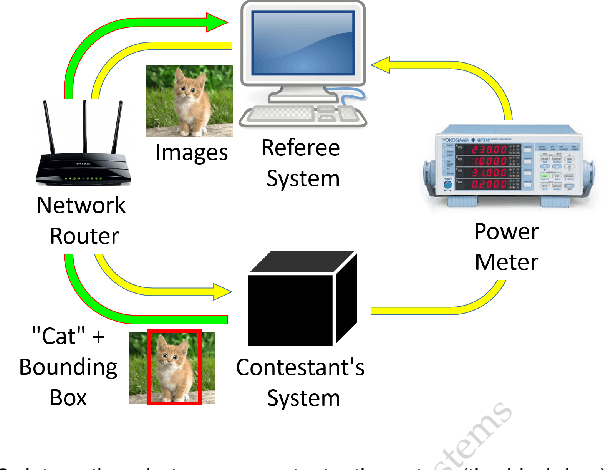
Computer vision has achieved impressive progress in recent years. Meanwhile, mobile phones have become the primary computing platforms for millions of people. In addition to mobile phones, many autonomous systems rely on visual data for making decisions and some of these systems have limited energy (such as unmanned aerial vehicles also called drones and mobile robots). These systems rely on batteries and energy efficiency is critical. This article serves two main purposes: (1) Examine the state-of-the-art for low-power solutions to detect objects in images. Since 2015, the IEEE Annual International Low-Power Image Recognition Challenge (LPIRC) has been held to identify the most energy-efficient computer vision solutions. This article summarizes 2018 winners' solutions. (2) Suggest directions for research as well as opportunities for low-power computer vision.
Differentiable Fine-grained Quantization for Deep Neural Network Compression
Oct 20, 2018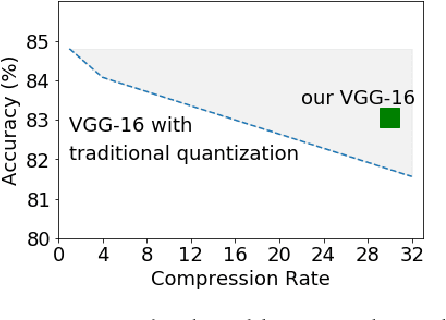
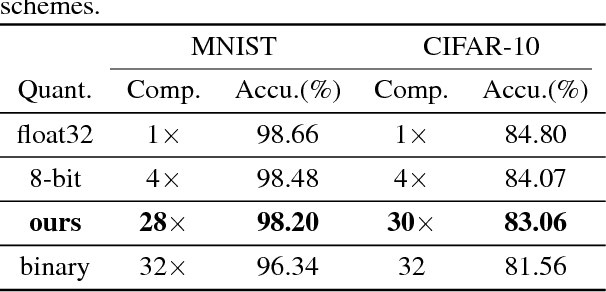

Neural networks have shown great performance in cognitive tasks. When deploying network models on mobile devices with limited resources, weight quantization has been widely adopted. Binary quantization obtains the highest compression but usually results in big accuracy drop. In practice, 8-bit or 16-bit quantization is often used aiming at maintaining the same accuracy as the original 32-bit precision. We observe different layers have different accuracy sensitivity of quantization. Thus judiciously selecting different precision for different layers/structures can potentially produce more efficient models compared to traditional quantization methods by striking a better balance between accuracy and compression rate. In this work, we propose a fine-grained quantization approach for deep neural network compression by relaxing the search space of quantization bitwidth from discrete to a continuous domain. The proposed approach applies gradient descend based optimization to generate a mixed-precision quantization scheme that outperforms the accuracy of traditional quantization methods under the same compression rate.